
nodejs OOMKilled kubernetes max-old-space-size Fix
Skilldham
Engineering deep-dives for developers who want real understanding.
Quick Answer
Your nodejs OOMKilled kubernetes max-old-space-size setup is incomplete - not wrong. Node.js uses two memory pools. The flag controls only one: the V8 heap. External Buffer memory sits outside it. Heavy uploads or streaming can push total RSS past your container limit through Buffer alone. The fix is --max-old-space-size-percentage plus fixing how you handle streams.
Your Node.js pod keeps dying with OOMKilled.
You Googled it. You set --max-old-space-size to 75% of your container limit. You redeployed. It crashed again.
You doubled the container memory. It crashed again - just took longer.
You are staring at Kubernetes event logs at 2am. Your pod has a 2GB limit. Your heap limit is 1.4GB. It still got OOMKilled.
Here's what is actually happening - and the fix that holds in production.
Why nodejs OOMKilled kubernetes max-old-space-size Keeps Failing
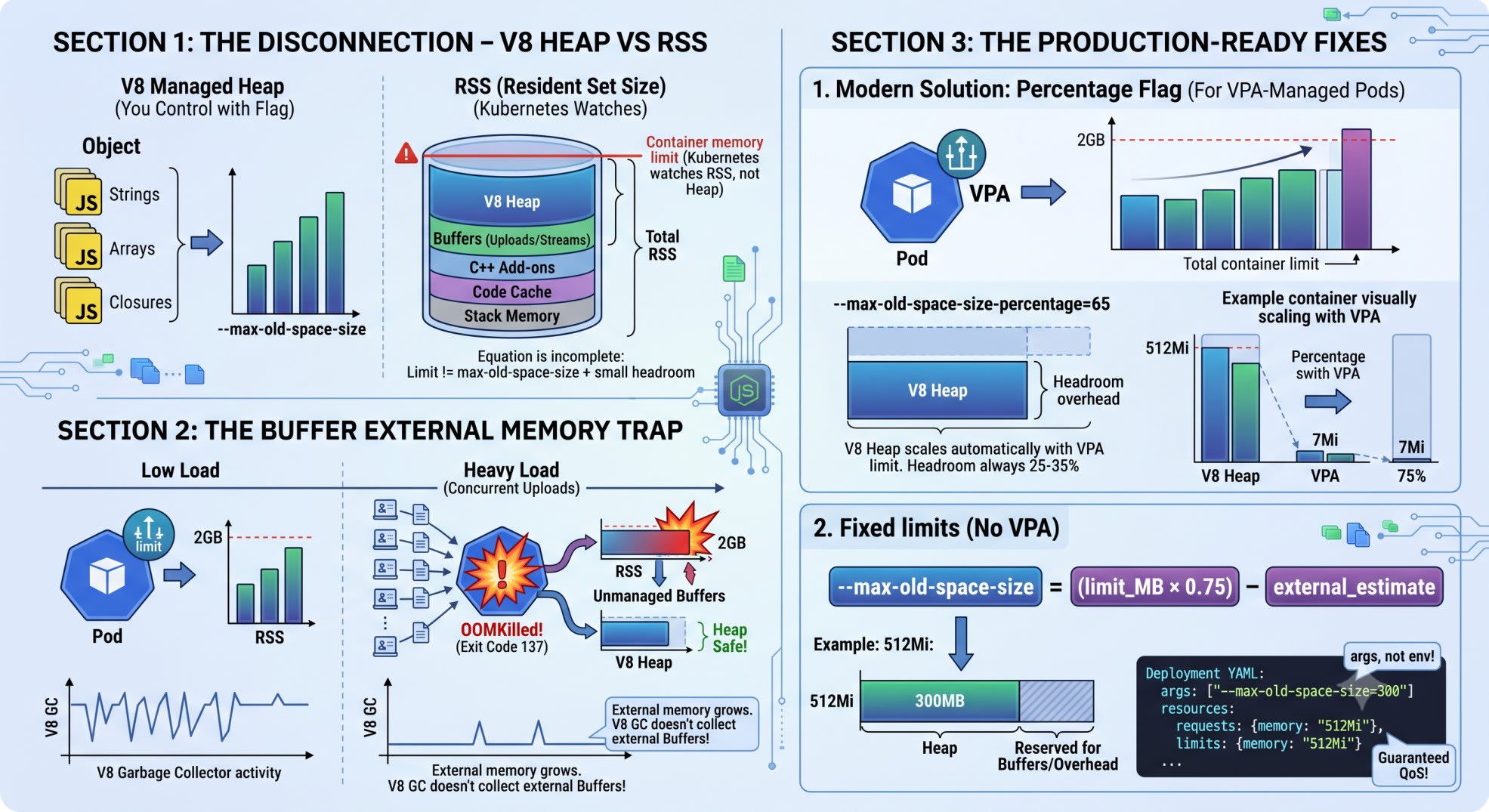
This is the core gap. Most developers model it as one equation:
container memory limit = --max-old-space-size + some headroomThat equation is wrong. Node.js has two separate memory pools. Only one obeys your flag.
V8 Managed Heap vs RSS
The --max-old-space-size flag controls the V8 managed heap. This is where your JavaScript objects live: strings, arrays, closures, objects.
Your pod's RSS (Resident Set Size) is the total physical memory the Node.js process uses. It includes the heap AND everything outside it.
What lives outside the V8 heap:
Buffer allocations - Buffer.alloc(), Buffer.from(), file reads, streams
C++ add-on memory - native modules, some database drivers
V8 code cache - compiled bytecode
Stack memory - per-thread call stacks
Kubernetes does not watch your heap. It watches RSS. When RSS exceeds resources.limits.memory, the Linux OOM killer fires. Your pod gets exit code 137.
The Numbers That Show the Gap
Show Image
Say your container limit is 2GB. You set --max-old-space-size=1400.
Your app handles file uploads. At peak, Buffer holds 450MB of external memory. Your heap is at 1.1GB - well under the 1.4GB cap.
Total RSS: 1.1GB heap + 450MB Buffer + 150MB overhead = 1.7GB. Fine.
Then 3 large uploads hit at once. Buffer climbs to 900MB.
Total RSS: 1.1GB + 900MB + 150MB = 2.15GB. OOMKilled.
Your heap never touched its limit. The flag was set correctly. The pod crashed anyway.
The Buffer External Memory Trap
Here is a minimal Express endpoint that reproduces this exact crash. Run it in a pod with a 512MB limit and --max-old-space-size=384 set. It will OOMKill under concurrent uploads.
javascript
// Wrong: buffering the entire file before processing
import express from 'express';
const app = express();
app.post('/upload', async (req, res) => {
const chunks = [];
for await (const chunk of req) {
chunks.push(chunk);
}
// entire file now in Buffer memory - held until this function returns
const fileBuffer = Buffer.concat(chunks);
res.json({ size: fileBuffer.length });
});What happens: each concurrent request holds a full Buffer until processing finishes. New Buffers pile up faster than GC can release them. V8's garbage collector does not manage external Buffer memory. From its view, the heap looks fine. RSS is climbing toward the limit.
Here is the fix:
javascript
// Correct: stream the file - never accumulate Buffer
import express from 'express';
import { createWriteStream } from 'fs';
import { pipeline } from 'stream/promises';
const app = express();
app.post('/upload', async (req, res) => {
const dest = createWriteStream('/tmp/upload-' + Date.now());
await pipeline(req, dest);
res.json({ saved: true });
});Memory stays flat under concurrent load. The Buffer is never accumulated.
Streaming is not always possible though. When you must buffer - you need to set your limits correctly too.
The Right Way to Set Memory Limits in Kubernetes
Static Sizing with --max-old-space-size
For pods with a fixed limit and no VPA, use this formula:
--max-old-space-size = (container_limit_MB × 0.75) - external_memory_estimateFor a 512MB container with moderate I/O:
(512 × 0.75) - 75 = 309MB → use 300Here is the complete Deployment YAML:
yaml
# Correct: Node.js Deployment with proper memory limits
apiVersion: apps/v1
kind: Deployment
metadata:
name: node-api
namespace: production
spec:
replicas: 2
selector:
matchLabels:
app: node-api
template:
metadata:
labels:
app: node-api
spec:
containers:
- name: node-api
image: your-registry/node-api:latest
command: ["node"]
args:
- "--max-old-space-size=300"
- "dist/server.js"
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
env:
- name: NODE_ENV
value: productionTwo things matter here.
The flag goes in args, not env. Passing it as an environment variable does nothing. Node.js reads memory flags from CLI arguments only.
Requests equal limits. This gives your pod Guaranteed QoS in Kubernetes. It will never be evicted under node memory pressure - only killed if it actually breaches the limit. Burstable QoS (requests below limits) means Kubernetes can evict it before it even OOMKills.
The Modern Fix: --max-old-space-size-percentage
Static sizing breaks with a Vertical Pod Autoscaler. VPA adjusts your memory limit dynamically. If it moves from 512Mi to 768Mi, your --max-old-space-size=300 is now too conservative. You waste 200MB of usable heap.
Node.js 18.11.0 added --max-old-space-size-percentage. You give it a percentage of total available memory - not a fixed MB value:
yaml
# Correct: percentage flag for VPA-managed pods
apiVersion: apps/v1
kind: Deployment
metadata:
name: node-api
namespace: production
spec:
replicas: 2
selector:
matchLabels:
app: node-api
template:
metadata:
labels:
app: node-api
spec:
containers:
- name: node-api
image: your-registry/node-api:latest
command: ["node"]
args:
- "--max-old-space-size-percentage=65"
- "dist/server.js"
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"At 65%, a 512Mi container gets ~332MB of heap. If VPA scales to 768Mi, the heap becomes ~499MB automatically. No redeployment needed.
Why 65% and not 75%? On any container doing I/O or using native addons, Buffer and overhead together consume 25-35% of RSS. 65% leaves that room.
When to Use Which Flag
ScenarioUseFixed limits, no VPA--max-old-space-size with calculated MBVPA-managed pods--max-old-space-size-percentage=65Node.js below 18.11Must use fixed MB (% flag does not exist)Heavy file streamingDrop to 55-60% and fix streaming tooPure JSON API, no I/OCan go to 70-75%
VPA Configuration for Node.js Pods
Pair this with your Deployment when using VPA:
yaml
# Correct: VPA config paired with --max-old-space-size-percentage
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: node-api-vpa
namespace: production
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: node-api
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: node-api
minAllowed:
memory: "256Mi"
cpu: "100m"
maxAllowed:
memory: "2Gi"
cpu: "2000m"
controlledResources: ["memory", "cpu"]VPA in Auto mode evicts and restarts pods with new resource values. The heap limit adjusts on each restart. With a fixed MB value, VPA scaling from 512Mi to 1Gi does nothing for the heap. It stays capped at the static MB you set.
Verifying Your Setup in Production
Run this on startup to confirm Node.js is reading limits correctly:
javascript
// Add to your health check or startup log
import v8 from 'v8';
import process from 'process';
function logMemoryConfig() {
const heapStats = v8.getHeapStatistics();
const heapLimitMB = Math.round(heapStats.heap_size_limit / 1024 / 1024);
const rssMB = Math.round(process.memoryUsage().rss / 1024 / 1024);
const externalMB = Math.round(process.memoryUsage().external / 1024 / 1024);
console.log({
heap_limit_mb: heapLimitMB,
current_rss_mb: rssMB,
external_buffer_mb: externalMB,
});
}
logMemoryConfig();What to check:
heap_limit_mb should match your calculated or percentage-based value
external_buffer_mb at startup should be under 20MB. If it is 100MB+ before any requests, a native module is eating memory during initialization
Under load, if external_buffer_mb climbs past 150MB on a 512Mi container, fix your streaming patterns
How Node.js 20+ Reads Container Memory
Node.js 20 added automatic cgroup v2 detection. It reads the memory limit from /sys/fs/cgroup/memory.max and uses it to size the V8 heap - no flags needed.
But it is not a full solution. Two problems:
It only adjusts the V8 heap. Buffer memory is still unaccounted for. And it uses around 80-85% of the container limit by default - leaving less room than you want for Buffer overhead.
It may also fail on cgroup v1 or older Kubernetes versions.
The explicit flag still wins. Auto-detection is a safety net, not a plan.
To check if Node.js is reading the cgroup limit inside your pod:
bash
# Run inside the pod
node -e "const v8 = require('v8'); console.log(v8.getHeapStatistics().heap_size_limit / 1024 / 1024 + 'MB')"If the output is 1.5GB or 4GB on a 512Mi pod, cgroup detection is not working. Set the flag explicitly.
Key Takeaways
nodejs OOMKilled kubernetes max-old-space-size set correctly is still not enough. Kubernetes watches RSS, not the V8 heap. Buffer memory lives in the gap.
Buffer allocations are not managed by V8's GC. Under concurrent I/O load, they pile up without triggering collection.
For a 512Mi container, set heap to 300MB - not 384MB. Leave 35% for Buffer, code cache, and stack.
Use --max-old-space-size-percentage=65 when running with VPA. The heap scales with the limit automatically.
The flag must be in args, not env. Environment variables are ignored for this.
Node.js 20+ auto-detection is a fallback. Use the flag anyway.
Stream files instead of buffering them. No flag setting compensates for accumulating full file Buffers under load.
FAQs
Why does my Node.js pod OOMKill even when --max-old-space-size is set correctly?
Because --max-old-space-size only limits the V8 heap. Buffer allocations, native module memory, and process overhead all live outside it. Kubernetes watches total RSS. If Buffer memory plus heap memory exceeds your container limit, the pod gets OOMKilled - even when the heap never hit its cap.
What is the right --max-old-space-size value for a 512MB container?
Around 300MB for apps doing I/O or using native modules. The formula: (limit × 0.75) minus an estimate for external memory, typically 50-100MB. For pure JSON API servers, you can push to 360MB. For heavy streaming, go lower and fix the streaming pattern too.
What is --max-old-space-size-percentage and when should I use it?
A flag added in Node.js 18.11.0 that sets the V8 heap as a percentage of total available container memory. Use it when pods are managed by VPA. The heap scales automatically when VPA adjusts the container limit. Set it to 65% for most apps.
Does Node.js 20 detect container memory automatically?
Yes. Node.js 20+ reads the cgroup v2 memory limit and uses it to size the heap without flags. But it uses around 80-85% of the limit by default - leaving less headroom for Buffer. Explicit flags are safer in production.
What is exit code 137 in Kubernetes?
Exit code 137 means the process was killed by signal 9 (SIGKILL). In Kubernetes, this is the Linux OOM killer terminating a container that exceeded its memory limit. It shows as OOMKilled in kubectl describe pod. The process is killed immediately - no cleanup.
Should --max-old-space-size go in an env variable or the command args?
In args. Node.js reads memory flags from CLI arguments passed directly to the node binary. NODE_OPTIONS=--max-old-space-size=300 does work as an alternative, but the args field in the Deployment YAML is more explicit and auditable.
Why do Buffer allocations not trigger Node.js garbage collection?
V8's GC manages the heap. Buffer allocations use native memory via malloc - outside the heap. The GC does not see it. Under sustained I/O, new Buffers are created faster than the heap GC cycles. External memory grows until RSS crosses the container limit.
Does setting memory requests equal limits help with OOMKilled?
Not directly. It does not prevent OOMKilled. But it gives your pod Guaranteed QoS. Kubernetes will not evict it under node memory pressure before it hits the OOM killer. With Burstable QoS, the pod can be evicted early, making the failure unpredictable. Guaranteed QoS makes the container limit the single boundary.
Conclusion
--max-old-space-size is not broken. It is just incomplete.
The V8 heap is one pool. RSS is everything. The gap is where OOMKilled lives.
Use the percentage flag on VPA. Fix streaming patterns. Put the flag in args. Verify with v8.getHeapStatistics() at startup.
If you hit the Node.js 24 native module issue while containerizing, the same environment gap causes a different class of failures - the Node.js 24 native module Docker build failures post covers that case. And if your app works in local Docker but breaks differently in the cluster, why local builds break in production covers the same environment-mismatch pattern.