
Prisma vs Drizzle - Which ORM for Next.js in 2026
Skilldham
Engineering deep-dives for developers who want real understanding.
You start a new Next.js project. Database is PostgreSQL. You need an ORM. Everyone says Prisma. But then you see Drizzle trending everywhere - Twitter, Reddit, YouTube. People saying it is faster, lighter, more TypeScript-native.
You spend two hours reading comparisons. Half say Prisma. Half say Drizzle. Nobody explains the actual trade-offs in a way that helps you decide for your specific project.
So you pick one, build for three months, and then hit a wall. Either Prisma's generated client is too heavy for your edge deployment, or Drizzle's query builder syntax is slowing your team down.
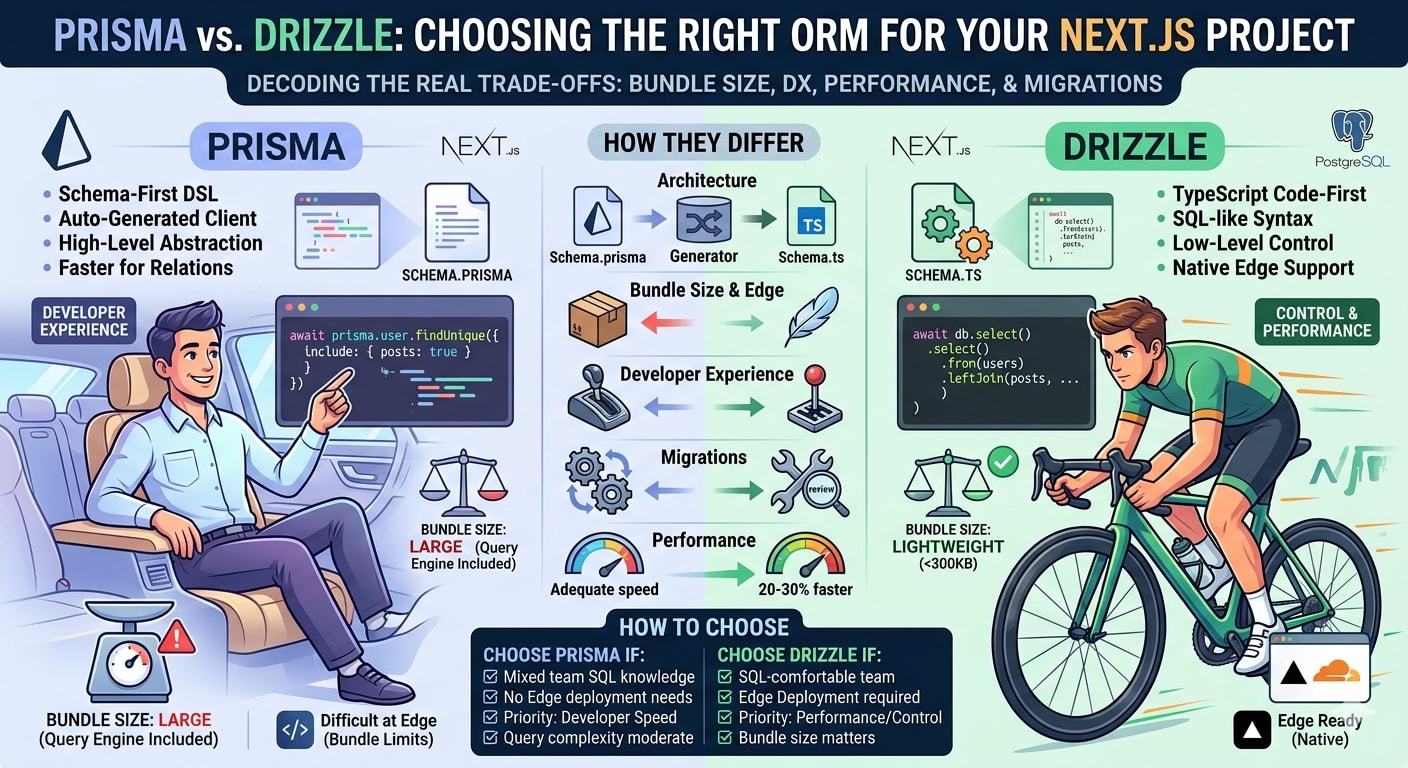
The prisma vs drizzle decision comes down to five specific differences that actually matter in production. Here is what those differences are, with real code from both sides, so you can make the right call before you write a single line of schema.
How Prisma and Drizzle Actually Work Differently
Before comparing features, the architecture difference matters. These two tools take fundamentally different approaches to the same problem, and that difference explains every trade-off between them.
Prisma uses a schema-first approach with a custom DSL. You write your models in schema.prisma, run a generator, and get a fully typed client that abstracts SQL completely. You never write SQL. You work with JavaScript objects and Prisma translates them to queries.
Drizzle uses a code-first approach. Your schema is TypeScript. Your queries look like SQL but written in TypeScript. You are always close to the actual SQL being executed.
typescript
// Wrong mental model - treating them as interchangeable
// They solve the same problem with completely different philosophies
// Prisma schema (schema.prisma - custom DSL)
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
createdAt DateTime @default(now())
}
// Drizzle schema (schema.ts - pure TypeScript)
import { pgTable, serial, text, timestamp } from 'drizzle-orm/pg-core'
export const users = pgTable('users', {
id: serial('id').primaryKey(),
email: text('email').notNull().unique(),
name: text('name'),
createdAt: timestamp('created_at').defaultNow(),
})typescript
// Correct mental model - different tools for different priorities
// Prisma query - abstracted, readable
const user = await prisma.user.findUnique({
where: { email: 'ravi@example.com' },
include: { posts: true },
})
// Drizzle query - SQL-like, explicit
const user = await db
.select()
.from(users)
.leftJoin(posts, eq(posts.userId, users.id))
.where(eq(users.email, 'ravi@example.com'))Neither approach is wrong. Prisma optimizes for developer experience and speed of writing queries. Drizzle optimizes for control and bundle size. The rest of the comparison flows from this core difference. This architectural choice is the same kind of decision as Next.js API routes vs Express - both valid, but built for different constraints.
Bundle Size and Edge Runtime - Where Drizzle Wins Clearly
This is the most practical difference for Next.js developers in 2026. If you are deploying to Vercel Edge Functions, Cloudflare Workers, or any edge runtime, Prisma has a real problem.
Prisma's generated client is large. The query engine alone is several megabytes. Edge runtimes have strict bundle size limits - Vercel Edge Functions cap at 1MB, Cloudflare Workers at 10MB but with slower cold starts for large bundles. Prisma regularly exceeds these limits.
typescript
// Wrong - Prisma in edge runtime will fail or be very slow
// app/api/users/route.ts - deployed as edge function
export const runtime = 'edge' // This causes problems with Prisma
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
export async function GET() {
// Cold start is slow, bundle is too large for edge
const users = await prisma.user.findMany()
return Response.json(users)
}typescript
// Correct - Drizzle works natively at the edge
// app/api/users/route.ts
export const runtime = 'edge' // Drizzle handles this fine
import { drizzle } from 'drizzle-orm/neon-http'
import { neon } from '@neondatabase/serverless'
import { users } from '@/db/schema'
const sql = neon(process.env.DATABASE_URL!)
const db = drizzle(sql)
export async function GET() {
const allUsers = await db.select().from(users)
return Response.json(allUsers)
}Drizzle with Neon's serverless driver is specifically built for this use case. The entire Drizzle package is under 300KB. For edge deployments, this is not a minor optimization - it is the difference between something that works and something that does not.
Prisma has made progress here with @prisma/adapter-neon and the Accelerate service, but it adds complexity and cost. Drizzle handles it natively. If your Next.js app runs any routes at the edge, this single point might decide the prisma vs drizzle question for you immediately.
Developer Experience and Query Writing - Where Prisma Wins
For team productivity, especially with developers who are not SQL-comfortable, Prisma's abstraction is genuinely valuable. The generated client is one of the best DX tools in the JavaScript ecosystem.
Filtering, sorting, pagination, and relation queries in Prisma are readable enough that a developer who has never touched SQL can write them correctly. Relations are particularly clean.
typescript
// Wrong - Drizzle relation query gets verbose for complex joins
// Fetching user with posts, each post with comments and author
const result = await db
.select({
userId: users.id,
userName: users.name,
postId: posts.id,
postTitle: posts.title,
commentId: comments.id,
commentBody: comments.body,
})
.from(users)
.leftJoin(posts, eq(posts.userId, users.id))
.leftJoin(comments, eq(comments.postId, posts.id))
.where(eq(users.id, userId))
// Then you manually reshape this flat result into nested objects
// Which is tedious and error-pronetypescript
// Correct - Prisma handles nested relations cleanly
const user = await prisma.user.findUnique({
where: { id: userId },
include: {
posts: {
include: {
comments: {
include: {
author: true,
},
},
},
},
},
})
// Already shaped as nested objects, ready to useFor a solo developer or small team shipping fast, Prisma's query API saves real time. The mental overhead of manually joining and reshaping data adds up across hundreds of queries.
Drizzle has improved this with its relations API, but it still requires more explicit setup than Prisma. The trade-off is honest - Drizzle gives you more control but asks you to do more work.
This is the same pattern as how JavaScript array methods save you from writing manual loops - higher-level abstractions speed you up when they fit your use case, and get in the way when they do not.
Migrations - Where Both Have Real Trade-offs
Migrations are where most developers hit unexpected friction with both tools. Neither approach is obviously better - they make different choices with different consequences.
Prisma generates migrations automatically from schema changes. You modify schema.prisma, run prisma migrate dev, and get a SQL migration file created for you. It is fast and requires minimal SQL knowledge.
bash
# Wrong - developers often skip reviewing generated migrations
npx prisma migrate dev --name add_user_role
# Prisma generates this automatically
# But the generated SQL might not be what you expected
# Especially for column renames, index changes, or data migrationstypescript
// Correct - always review generated migrations before applying
// migrations/20240501_add_user_role.sql
-- Prisma generated this:
ALTER TABLE "User" ADD COLUMN "role" TEXT NOT NULL DEFAULT 'USER';
-- Review questions:
-- Is the default value right for existing rows?
-- Should this be an enum instead of text?
-- Do we need an index on this column?
// And in schema.prisma - make intentions explicit
model User {
id Int @id @default(autoincrement())
email String @unique
role String @default("USER") // Consider: enum Role { USER ADMIN }
}Drizzle takes a different approach. You write migrations manually or use drizzle-kit to generate them, but the expectation is that you understand what SQL is being executed.
typescript
// Drizzle - schema change
export const users = pgTable('users', {
id: serial('id').primaryKey(),
email: text('email').notNull().unique(),
role: text('role', { enum: ['USER', 'ADMIN'] }).notNull().default('USER'),
})
// drizzle-kit generates migration SQL
// But you review and understand it before runningFor teams with SQL experience, Drizzle's approach produces cleaner, more intentional migrations. For teams moving fast without deep SQL knowledge, Prisma's automatic generation is faster even if it occasionally needs manual adjustment.
Performance in Real Production Workloads
The performance difference between prisma vs drizzle in real applications is smaller than the benchmarks suggest, but it exists in specific scenarios.
Prisma adds overhead because queries go through the query engine abstraction layer. For simple queries on small datasets, this overhead is invisible. For complex queries, high-traffic endpoints, or large result sets, the difference becomes measurable.
typescript
// Wrong - Prisma's N+1 problem if you're not careful
const posts = await prisma.post.findMany()
// This fires N additional queries for N posts
for (const post of posts) {
const author = await prisma.user.findUnique({
where: { id: post.authorId }
})
console.log(post.title, author.name)
}typescript
// Correct - use include to prevent N+1 in Prisma
const posts = await prisma.post.findMany({
include: {
author: {
select: { name: true, email: true }
}
}
})
// One query, no N+1 problem
// Drizzle - equivalent with explicit join
const postsWithAuthors = await db
.select({
title: posts.title,
authorName: users.name,
authorEmail: users.email,
})
.from(posts)
.leftJoin(users, eq(users.id, posts.authorId))In real-world testing on production workloads, Drizzle is typically 20-30% faster on equivalent queries. For most applications, 20-30% faster on database queries that take 5ms is not a meaningful difference. For high-traffic APIs handling thousands of requests per second, it matters.
Skilldham runs on Prisma with NeonDB. For the current traffic levels, Prisma's performance is completely adequate and the developer experience savings are worth more than the performance headroom Drizzle would provide.
How to Actually Choose Between Prisma and Drizzle
The decision tree is simpler than the comparison makes it seem.
Choose Prisma when your team includes developers who are not SQL-comfortable, you are not deploying to edge runtimes, you want the fastest path to a working data layer, and your query complexity is moderate.
Choose Drizzle when you are deploying to edge runtimes like Cloudflare Workers or Vercel Edge, your team is SQL-comfortable and values control over abstraction, bundle size is a real constraint in your deployment, or you need maximum query performance for high-traffic endpoints.
typescript
// Decision helper - honest checklist
const projectProfile = {
edgeRuntime: false, // true → Drizzle strongly preferred
teamSQLKnowledge: 'mixed', // 'low' → Prisma, 'high' → Drizzle
bundleSizeSensitive: false, // true → Drizzle
queryComplexity: 'moderate', // 'high' → consider Drizzle
teamSize: 'small', // matters less than the above
shippingSpeed: 'fast', // → Prisma
}
// Scoring
// edgeRuntime true → Drizzle (non-negotiable)
// teamSQLKnowledge low → Prisma
// bundleSizeSensitive true → Drizzle
// shippingSpeed fast + small team → PrismaOne more honest point. Both tools are good. Both are actively maintained. Both work in production at scale. The companies that get into trouble are the ones who chose based on Twitter hype rather than their actual constraints.
If you are starting a new project today with no specific edge deployment requirement and a small team, start with Prisma. It is faster to get running, easier to onboard new developers, and more than adequate for most applications. Migrate to Drizzle if and when you hit a specific constraint that Prisma cannot handle.
Key Takeaway
The prisma vs drizzle decision is not about which ORM is objectively better. It is about which trade-offs match your project's actual constraints.
Prisma wins on developer experience, relation queries, and speed of development
Drizzle wins on bundle size, edge runtime support, raw performance, and SQL control
Edge deployment is the one scenario where Drizzle is the clear choice - Prisma's bundle size makes it difficult
For most Next.js applications with no edge requirement, Prisma is faster to build with and easier to maintain
Both produce production-grade results - choose based on constraints, not hype
You can always migrate later - the schema concepts transfer, only the query syntax changes
FAQs
Is Drizzle faster than Prisma in production? In benchmarks, Drizzle is typically 20-40% faster on equivalent queries because it has less abstraction overhead. In real applications handling moderate traffic, this difference is rarely noticeable. For high-traffic APIs or edge deployments where every millisecond counts, Drizzle's performance advantage becomes meaningful. For most Next.js applications, both are fast enough.
Can I use Prisma with edge runtimes like Cloudflare Workers? Prisma has experimental edge support through Prisma Accelerate and adapter packages, but it adds cost and complexity. Drizzle was built with edge runtimes as a first-class target and works natively with Cloudflare Workers, Vercel Edge Functions, and Neon's serverless driver. If edge deployment is a requirement, Drizzle is the simpler choice.
Is Drizzle hard to learn coming from Prisma? The main learning curve is shifting from Prisma's abstracted API to Drizzle's SQL-like query builder. Developers comfortable with SQL adapt quickly - usually within a few days. Developers who learned database access through Prisma and have limited SQL knowledge find the transition harder. Drizzle's relations API reduces some of this friction but does not eliminate it.
Which ORM should I use for a solo developer or small startup? Prisma is almost always the better choice for solo developers and small startups where shipping speed matters more than performance optimization. The developer experience is better, getting to a working data layer is faster, and you can always migrate to Drizzle if you hit specific constraints. Do not optimize for performance problems you do not have yet.
Does Drizzle support all the same databases as Prisma? Both support PostgreSQL, MySQL, and SQLite. Prisma also supports MongoDB, SQL Server, and CockroachDB. Drizzle supports Turso, PlanetScale, and has better native support for serverless database drivers like Neon and Cloudflare D1. The database you are using and where it is hosted can influence which ORM has better native support.
Can I use Prisma and Drizzle together in the same project? Technically yes, but it is not recommended. Having two ORMs in one project doubles the dependency overhead and creates confusion about which tool to use where. A better approach is to pick one for the main application and use raw SQL or a query builder for specific performance-critical queries that neither ORM handles well.
How does migration handling compare between Prisma and Drizzle? Prisma generates migrations automatically from schema changes and handles them through the Prisma CLI. Drizzle generates migrations through drizzle-kit but expects you to understand and review the SQL. Prisma is faster for teams without SQL expertise. Drizzle gives more control and produces cleaner migrations for teams that understand what they are executing. Both approaches work reliably in production.