
LangChain v1 Custom Memory Migration: What Actually Breaks
Skilldham
Engineering deep-dives for developers who want real understanding.
LangChain hit 1.0 GA in October 2025. Most of the provider integrations didn't change much. Your memory layer did.
If you built a production app on AgentExecutor and RunnableWithMessageHistory, with a custom BaseChatMessageHistory backed by Postgres or Cosmos DB, that code does not run anymore. Not "deprecated with a warning." It does not run.
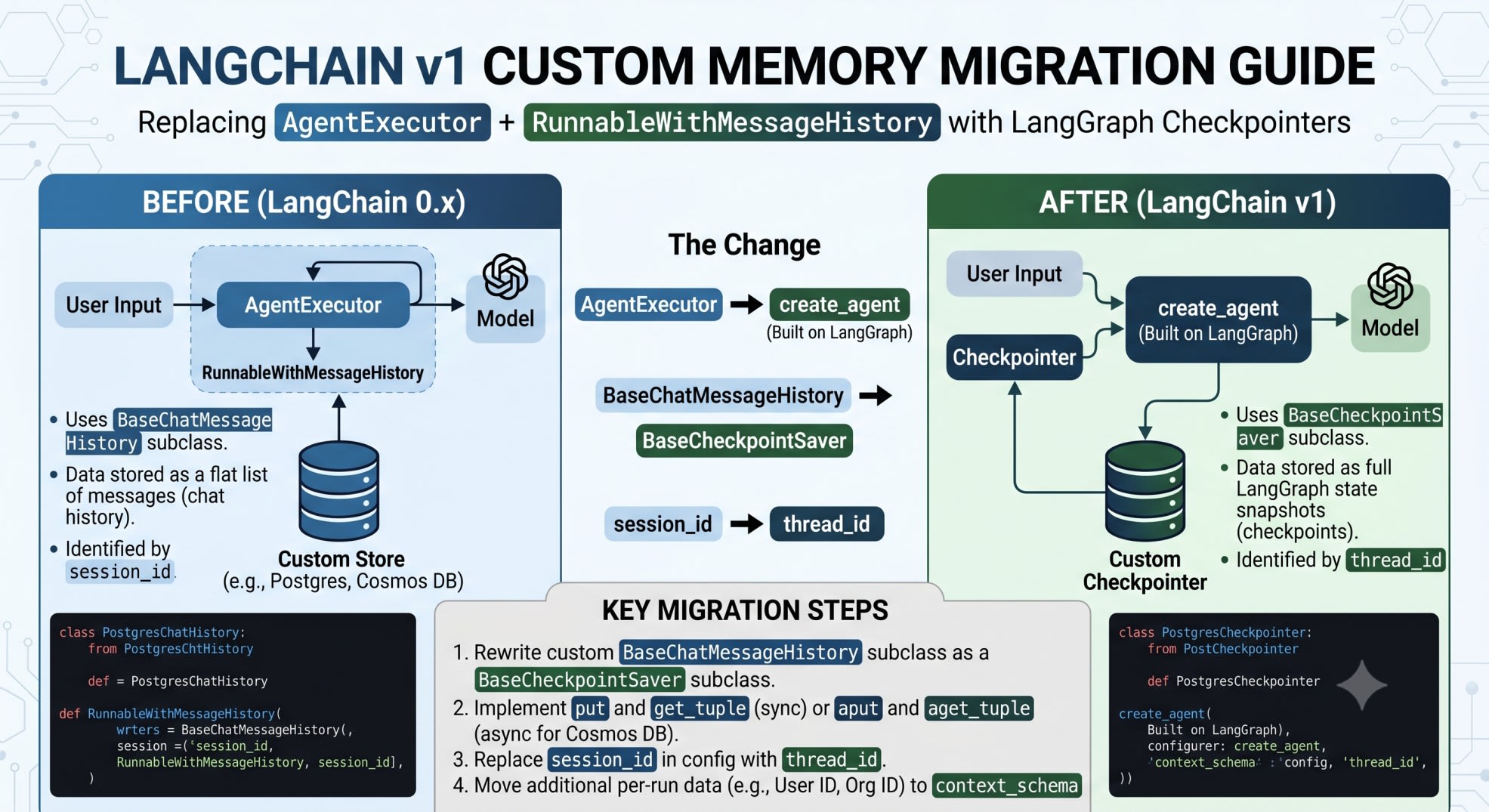
That's the LangChain v1 custom memory migration this post walks through. You search for a fix. You find the official migration guide. It tells you to swap create_react_agent for create_agent. It does not mention your custom memory store at all.
Here's what actually breaks, and the exact steps to fix it.
Quick Answer
A LangChain v1 custom memory migration means replacing AgentExecutor + RunnableWithMessageHistory with create_agent and a LangGraph checkpointer. Your custom memory backend (Postgres, Cosmos DB) doesn't get migrated automatically. You rewrite it as a BaseCheckpointSaver subclass, swap session_id for thread_id, and use context_schema for any other per-run data you were passing through configurable.
What a LangChain v1 Custom Memory Migration Breaks First
What LangChain v1 Actually Changed
AgentExecutor is gone from the main langchain package. So is the old RunnableWithMessageHistory pattern for agents. Both moved to a separate langchain-legacy package.
In their place: create_agent, built directly on LangGraph. It runs the model in a loop, calling tools until there are no more tool calls left. Memory is no longer a wrapper you bolt on. It's a checkpointer you pass in at creation time.
This is not a rename. The whole persistence model changed underneath it.
The Pattern That Used to Work
Before v1, your setup probably looked like this. A function returns a BaseChatMessageHistory for a given session_id. RunnableWithMessageHistory wraps your agent executor and calls that function automatically.
I've shipped this exact pattern on three different client projects, all hitting Postgres for chat history. It worked fine for two years. Then v1 landed and none of it imported anymore.
The Old Pattern: A Custom Postgres Memory Store
The BaseChatMessageHistory Subclass
python
# Before (LangChain 0.x): custom Postgres-backed chat history
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict
import json
class PostgresChatHistory(BaseChatMessageHistory):
def __init__(self, session_id: str, conn):
self.session_id = session_id
self.conn = conn
@property
def messages(self) -> list[BaseMessage]:
with self.conn.cursor() as cur:
cur.execute(
"SELECT message FROM chat_history WHERE session_id = %s ORDER BY created_at",
(self.session_id,),
)
rows = cur.fetchall()
return messages_from_dict([json.loads(row[0]) for row in rows])
def add_message(self, message: BaseMessage) -> None:
with self.conn.cursor() as cur:
cur.execute(
"INSERT INTO chat_history (session_id, message) VALUES (%s, %s)",
(self.session_id, json.dumps(message_to_dict(message))),
)
self.conn.commit()
def clear(self) -> None:
with self.conn.cursor() as cur:
cur.execute("DELETE FROM chat_history WHERE session_id = %s", (self.session_id,))
self.conn.commit()This is a reasonable amount of code. It's also exactly the kind of code that doesn't have a "just rename this" upgrade path.
Wiring It Into RunnableWithMessageHistory
python
# Before (LangChain 0.x): wiring it up
from langchain.agents import AgentExecutor
from langchain_core.runnables.history import RunnableWithMessageHistory
def get_session_history(session_id: str):
return PostgresChatHistory(session_id, pg_conn)
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_with_history = RunnableWithMessageHistory(
agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
agent_with_history.invoke(
{"input": "What's my order status?"},
config={"configurable": {"session_id": "user-123"}},
)This is the pattern in the unanswered forum thread. The developer got as far as "AgentExecutor is gone" and then stalled, because nothing tells you what replaces this specific wiring.
The New Pattern: create_agent With a Custom Checkpointer
Why You Can't Just Reuse Your Old History Class
BaseChatMessageHistory stores a flat list of messages for a session. A LangGraph checkpointer stores something bigger: the full graph state, at every step, for a thread_id. It's built for resuming mid-run, not just replaying past messages.
That's why your old class won't plug in directly. You're not migrating a list. You're migrating to a different storage shape.
Subclassing BaseCheckpointSaver
python
# After (LangChain v1): custom checkpointer over the same Postgres table
from langgraph.checkpoint.base import BaseCheckpointSaver, CheckpointTuple
import json
class PostgresCheckpointer(BaseCheckpointSaver):
def __init__(self, conn):
self.conn = conn
def put(self, config, checkpoint, metadata, new_versions):
thread_id = config["configurable"]["thread_id"]
with self.conn.cursor() as cur:
cur.execute(
"""
INSERT INTO agent_checkpoints (thread_id, checkpoint, metadata)
VALUES (%s, %s, %s)
ON CONFLICT (thread_id)
DO UPDATE SET checkpoint = EXCLUDED.checkpoint, metadata = EXCLUDED.metadata
""",
(thread_id, json.dumps(checkpoint), json.dumps(metadata)),
)
self.conn.commit()
return config
def get_tuple(self, config):
thread_id = config["configurable"]["thread_id"]
with self.conn.cursor() as cur:
cur.execute(
"SELECT checkpoint, metadata FROM agent_checkpoints WHERE thread_id = %s",
(thread_id,),
)
row = cur.fetchone()
if not row:
return None
checkpoint, metadata = row
return CheckpointTuple(config, json.loads(checkpoint), json.loads(metadata))
def list(self, config, *, filter=None, before=None, limit=None):
return iter([]) # see "What's Still Rough" below before shipping this as-is
def put_writes(self, config, writes, task_id):
pass # stores pending writes between graph steps - needed for multi-step tool calls
agent = create_agent(
model="openai:gpt-4o",
tools=tools,
checkpointer=PostgresCheckpointer(pg_conn),
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my order status?"}]},
config={"configurable": {"thread_id": "user-123"}},
)Notice session_id became thread_id. That's not cosmetic. thread_id is what LangGraph uses everywhere - checkpoints, time travel, the LangSmith UI all key off it.
If your team only needs basic Postgres persistence, LangGraph ships PostgresSaver out of the box and you can skip writing this class entirely. You only need the custom subclass when your storage doesn't have an official saver - which is exactly the Cosmos DB situation below.
If you're building agent infrastructure from scratch rather than migrating, our guide to building a RAG system covers the same custom-store pattern from the other direction.
Replacing session_id: thread_id and context_schema
thread_id Scopes the Conversation
thread_id controls one thing: which checkpoint history this run reads and writes. Same thread_id across calls means the agent remembers the conversation. New thread_id means a fresh start.
This is the direct replacement for the session_id you passed into get_session_history.
context_schema Carries Per-Run Data
In the old pattern, people often stuffed extra identifiers (user ID, org ID) into the same config dict as session_id. In v1, that data has its own home: context_schema.
python
# After (LangChain v1): context_schema for per-run identifiers
from dataclasses import dataclass
@dataclass
class UserContext:
user_id: str
org_id: str
agent = create_agent(
model="openai:gpt-4o",
tools=tools,
context_schema=UserContext,
checkpointer=PostgresCheckpointer(pg_conn),
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my order status?"}]},
config={"configurable": {"thread_id": "user-123"}},
context=UserContext(user_id="user-123", org_id="acme-corp"),
)thread_id and context are usually passed together. thread_id says which conversation. context says who, and any other detail your tools or middleware need to read mid-run. This pairing is also how MCP-based tools receive scoped identity - see our Model Context Protocol explainer if that distinction is new to you.
Migrating a Cosmos DB-Backed Memory Store
There's No Official Cosmos DB Checkpointer
This is the part nobody's content covers. LangGraph ships official savers for Postgres, SQLite, and a couple of managed services. Cosmos DB isn't one of them, as of this writing. If your team is on Azure with Cosmos as the memory backend, you're writing the BaseCheckpointSaver subclass yourself, the same way the Postgres example above does, but against the Cosmos SDK instead of psycopg.
The shape is identical: put, get_tuple, list, put_writes. Map thread_id to your Cosmos partition key, and the rest of create_agent doesn't know or care that it isn't Postgres underneath.
Going Async-First
One real difference: the Cosmos Python SDK is async-first. BaseCheckpointSaver expects async methods too, when you're running an async app - aget_tuple, aput, aput_writes, adelete_thread.
python
# After (LangChain v1): async variant for Cosmos DB
class CosmosCheckpointer(BaseCheckpointSaver):
def __init__(self, container):
self.container = container
async def aget_tuple(self, config):
thread_id = config["configurable"]["thread_id"]
try:
item = await self.container.read_item(thread_id, partition_key=thread_id)
except Exception:
return None
return CheckpointTuple(config, item["checkpoint"], item["metadata"])
async def aput(self, config, checkpoint, metadata, new_versions):
thread_id = config["configurable"]["thread_id"]
await self.container.upsert_item({
"id": thread_id,
"checkpoint": checkpoint,
"metadata": metadata,
})
return configIf your old PostgresChatHistory class was synchronous and your new agent runs inside an async FastAPI route, this is where teams lose an afternoon. Match sync-to-sync and async-to-async - don't mix them inside one checkpointer.
What's Still Rough in Self-Hosted v1 Memory
The "No checkpointer set" Trap
If you self-host and forget to pass checkpointer=, you don't get a soft fallback. You get a hard failure the first time something tries to read state - the error reads GraphValueError: No checkpointer set, and it shows up at retrieval time, not at agent creation time, which makes it confusing to trace back.
On LangSmith's managed deployment, a checkpointer gets provisioned automatically. Self-hosted, you don't get that. Pass one explicitly, even InMemorySaver() for local testing, or you will hit this.
list() and delete_thread Aren't Optional Stubs in Production
In the example above, list() returns an empty iterator. That's fine for getting invoke() working. It is not fine in production - list() backs time-travel debugging in the LangGraph UI, and delete_thread is what GDPR-style data deletion requests call. If your compliance team needs "delete this user's conversation history" to actually work, implement both for real before you ship this.
Key Takeaways
LangChain v1's create_agent replaces AgentExecutor, and a LangGraph checkpointer replaces RunnableWithMessageHistory - this is a storage-shape change, not a rename
Your old BaseChatMessageHistory subclass does not plug into the new system; you rewrite it as a BaseCheckpointSaver with put, get_tuple, list, and put_writes
session_id becomes thread_id; any other per-user data (user ID, org ID) moves to context_schema
There's no official LangGraph checkpointer for Cosmos DB - map your partition key to thread_id and write the async variant yourself
Forgetting checkpointer= on a self-hosted app throws GraphValueError: No checkpointer set at read time, not creation time
Don't ship list() or delete_thread as empty stubs if you have any audit or data-deletion requirements
FAQs
Why is AgentExecutor gone in LangChain v1?
LangChain rebuilt its agent layer directly on LangGraph for v1. AgentExecutor and the old chain-based agent pattern moved out of the main package into a separate langchain-legacy package, rather than being deprecated in place.
Do I have to rewrite my entire custom memory store for v1?
You have to rewrite the wiring class, not necessarily your database schema. A BaseCheckpointSaver subclass can read and write to the same Postgres or Cosmos DB tables your old BaseChatMessageHistory used - you're changing the Python interface, not the storage.
What replaces session_id from RunnableWithMessageHistory?
thread_id, passed inside config["configurable"]. It works the same way conceptually - same ID across calls keeps the conversation going - but it's now tied to LangGraph's checkpoint system instead of a flat message list.
Can I keep using RunnableWithMessageHistory in v1?
Only if you stay on the langchain-legacy package and avoid create_agent entirely. The two systems don't mix - create_agent only accepts a checkpointer, not a RunnableWithMessageHistory wrapper.
Does LangChain provide an official Cosmos DB checkpointer?
No, not as of this writing. LangGraph ships official savers for Postgres, SQLite, and a few managed platforms. For Cosmos DB, you subclass BaseCheckpointSaver yourself, the same pattern shown for Postgres in this post.
What's the difference between thread_id and context_schema?
thread_id scopes which conversation history gets loaded - it controls persistence. context_schema carries extra per-run data, like user ID or org ID, that your tools and middleware can read but that doesn't affect which checkpoint gets loaded.
Why did my agent throw "No checkpointer set" after upgrading?
You're calling something that reads graph state - often get_state() - without having passed a checkpointer when you created the agent. On self-hosted deployments, nothing provisions one for you automatically. Pass checkpointer=InMemorySaver() at minimum, or a persistent one for production.
Is LangGraph's PostgresSaver enough, or do I need a custom checkpointer?
If you're on plain Postgres with no special schema requirements, PostgresSaver from langgraph-checkpoint-postgres is enough and you should use it instead of hand-rolling one. Write a custom BaseCheckpointSaver only when you're on a backend without an official saver, like Cosmos DB, or when you need to reuse an existing table structure you can't change.
Conclusion
LangChain v1's memory model isn't broken - it's just different, and the official docs assume you're starting clean. Once you see that BaseCheckpointSaver is doing the same job your BaseChatMessageHistory class did, just against a bigger state shape, the migration stops being mysterious.
If you're also working through other framework-breaking upgrades right now, our Prisma 7 migration guide covers a similar driver-adapter style gap from the database side.